[1주차] 컨테이너 격리 & 네트워크 및 보안 - #2
CloudNet@ 가시다님이 진행하는 KANS Study 3기 스터디 내용 참고.
3. 컨테이너 격리
리눅스 프로세스 격리 기술 발전

- 도커 없이 컨테이너 만들기 1 : Chroot + 탈옥 - Youtube , Github , Docs
- chroot root directory : user 디렉터리를 user 프로세스에게 root 디렉터리를 속임
# [터미널1] 관리자 전환
sudo su -
whoami
#
cd /tmp
mkdir myroot
# chroot 사용법 : [옵션] NEWROOT [커맨드]
chroot myroot /bin/sh
chroot: failed to run command ‘/bin/sh’: No such file or directory
#
tree myroot
which sh
ldd /bin/sh
# 바이러리 파일과 라이브러리 파일 복사
mkdir -p myroot/bin
cp /usr/bin/sh myroot/bin/
mkdir -p myroot/{lib64,lib/x86_64-linux-gnu}
tree myroot
cp /lib/x86_64-linux-gnu/libc.so.6 myroot/lib/x86_64-linux-gnu/
cp /lib64/ld-linux-x86-64.so.2 myroot/lib64
tree myroot/
#
w
--------------------
ls
exit
--------------------
#
which ls
ldd /usr/bin/ls
#
cp /usr/bin/ls myroot/bin/
mkdir -p myroot/bin
cp /lib/x86_64-linux-gnu/{libselinux.so.1,libc.so.6,libpcre2-8.so.0} myroot/lib/x86_64-linux-gnu/
cp /lib64/ld-linux-x86-64.so.2 myroot/lib64
tree myroot
#
chroot myroot /bin/sh
--------------------
ls /
## 탈출 가능한지 시도
cd ../../../
ls /
# 아래 터미널2와 비교 후 빠져나오기
exit
--------------------
# chroot 요약 : 경로를 모으고(패키징), 경로에 가둬서 실행(격리)
# [터미널2]
# chroot 실행한 터미널1과 호스트 디렉터리 비교
ls /- chroot 에서 ps 실행해보기 - Link
# copy ps
ldd /usr/bin/ps;
cp /usr/bin/ps /tmp/myroot/bin/;
cp /lib/x86_64-linux-gnu/{libprocps.so.8,libc.so.6,libsystemd.so.0,liblzma.so.5,libgcrypt.so.20,libgpg-error.so.0,libzstd.so.1,libcap.so.2} /tmp/myroot/lib/x86_64-linux-gnu/;
mkdir -p /tmp/myroot/usr/lib/x86_64-linux-gnu;
cp /usr/lib/x86_64-linux-gnu/liblz4.so.1 /tmp/myroot/usr/lib/x86_64-linux-gnu/;
cp /lib64/ld-linux-x86-64.so.2 /tmp/myroot/lib64/;
# copy mount
ldd /usr/bin/mount;
cp /usr/bin/mount /tmp/myroot/bin/;
cp /lib/x86_64-linux-gnu/{libmount.so.1,libc.so.6,libblkid.so.1,libselinux.so.1,libpcre2-8.so.0} /tmp/myroot/lib/x86_64-linux-gnu/;
cp /lib64/ld-linux-x86-64.so.2 /tmp/myroot/lib64/;
# copy mkdir
ldd /usr/bin/mkdir;
cp /usr/bin/mkdir /tmp/myroot/bin/;
cp /lib/x86_64-linux-gnu/{libselinux.so.1,libc.so.6,libpcre2-8.so.0} /tmp/myroot/lib/x86_64-linux-gnu/;
cp /lib64/ld-linux-x86-64.so.2 /tmp/myroot/lib64/;
# tree 확인
tree myroot
#
chroot myroot /bin/sh
---------------------
# 왜 ps가 안될까요?
ps
Error, do this: mount -t proc proc /proc
#
mount -t proc proc /proc
mount: /proc: mount point does not exist.
#
mkdir /proc
mount -t proc proc /proc
mount -t proc
# ps는 /proc 의 실시간 정보를 활용
ps
ps auf
ps aux
ls -l /proc
exit
---------------------
# 실습 시 사용한 proc 마운트 제거
mount -t proc
sudo umount /tmp/myroot/proc
mount -t proc



ps 명령이 실행됩니다.

- 남이 만든 이미지 chroot 해보기 : 컨테이너 이미지는 실행되는 프로세스의 동작에 필요한 모든 관련 파일을 묶어서 패키징
#
mkdir nginx-root
tree nginx-root
# nginx 컨테이너 압축 이미지를 받아서 압축 풀기
docker export $(docker create nginx) | tar -C nginx-root -xvf -;
docker images
#
tree -L 1 nginx-root
tree -L 2 nginx-root | more
#
chroot nginx-root /bin/sh
---------------------
ls /
#
nginx -g "daemon off;"
# 터미널1에서 아래 확인 후 종료
CTRL +C # nginx 실행 종료
exit
---------------------
# [터미널2]
## 루트 디렉터리 비교 및 확인
ls /
ps -ef |grep nginx
curl localhost:80
sudo ss -tnlp
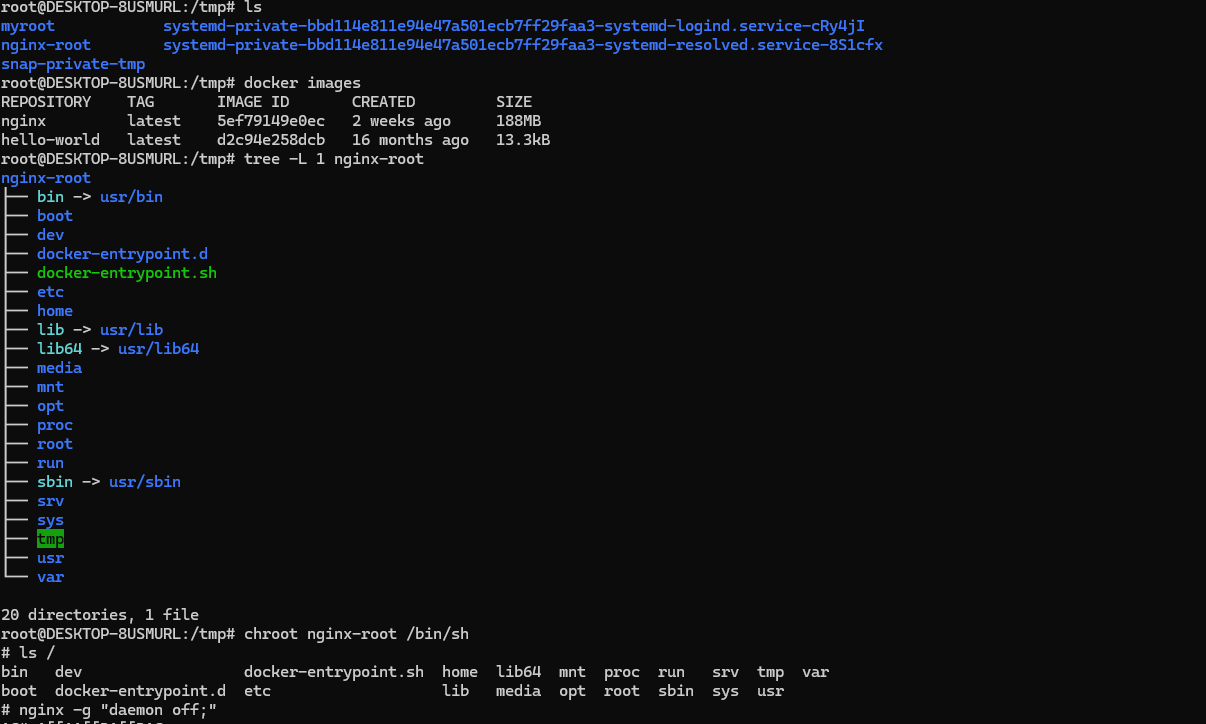

nginx 실행이 확인됩니다.
- 탈옥 코드 -> 컴파일하고 new-root 에 복사
vi escape_chroot.c
#include <sys/stat.h>
#include <unistd.h>
int main(void)
{
mkdir(".out", 0755);
chroot(".out");
chdir("../../../../../");
chroot(".");
return execl("/bin/sh", "-i", NULL);
}
# 컴파일
gcc -o myroot/escape_chroot escape_chroot.c
tree -L 1 myroot
file myroot/escape_chroot
# chroot 실행
chroot myroot /bin/sh
-----------------------
ls /
cd ../../
cd ../../
ls /
# 탈출!
./escape_chroot
ls /
# 종료
exit
exit
-----------------------
# [터미널2]
## 루트 디렉터리 비교 및 확인
ls /

탈옥 성공했습니다.
- 도커 없이 컨테이너 만들기 2 : 마운트 네임스페이스 + Pivot_root
- chroot 차단을 위해서, pivot_root + mount ns(호스트 영향 격리) 를 사용 : 루트 파일 시스템을 변경(부착 mount) + 프로세스 환경 격리

- 마운트 네임스페이스 : 마운트 포인트를 격리(unshare)



- 마운트 네임스페이스
주요 명령어
pivot_root
# pivot_root [new-root] [old-root]
## 사용법은 심플합니다 ~ new-root와 old-root 경로를 주면 됩니다
mount
# mount -t [filesystem type] [device_name] [directory - mount point]
## root filesystem tree에 다른 파일시스템을 붙이는 명령
## -t : filesystem type ex) -t tmpfs (temporary filesystem : 임시로 메모리에 생성됨)
## -o : 옵션 ex) -o size=1m (용량 지정 등 …)
## 참고) * /proc/filesystems 에서 지원하는 filesystem type 조회 가능
unshare
# unshare [options] [program] [arguments]]
## "새로운 네임스페이스를 만들고 나서 프로그램을 실행" 하는 명령어입니다
# [터미널1]
unshare --mount /bin/sh
-----------------------
# 아래 터미널2 호스트 df -h 비교 : mount unshare 시 부모 프로세스의 마운트 정보를 복사해서 자식 네임스페이스를 생성하여 처음은 동일
df -h
-----------------------
# [터미널2]
df -h
# [터미널1]
-----------------------
#
mkdir new_root
mount -t tmpfs none new_root
ls -l
tree new_root
## 마운트 정보 비교 : 마운트 네임스페이스를 unshare
df -h
mount | grep new_root
findmnt -A
## 파일 복사 후 터미널2 호스트와 비교
cp -r myroot/* new_root/
tree new_root/
-----------------------
# [터미널2]
cd /tmp
ls -l
tree new_root
df -h
mount | grep new_root
findmnt -A
## 안보이는 이유 : 마운트 네임스페이스를 unshare 된 상태
tree new_root/
- pivot_root



주요 명령어
pivot_root
# pivot_root [new-root] [old-root]
## 사용법은 심플합니다 ~ new-root와 old-root 경로를 주면 됩니다
mount
# mount -t [filesystem type] [device_name] [directory - mount point]
## root filesystem tree에 다른 파일시스템을 붙이는 명령
## -t : filesystem type ex) -t tmpfs (temporary filesystem : 임시로 메모리에 생성됨)
## -o : 옵션 ex) -o size=1m (용량 지정 등 …)
## 참고) * /proc/filesystems 에서 지원하는 filesystem type 조회 가능
unshare
# unshare [options] [program] [arguments]]
## "새로운 네임스페이스를 만들고 나서 프로그램을 실행" 하는 명령어입니다
# [터미널1]
unshare --mount /bin/sh
-----------------------
# 아래 터미널2 호스트 df -h 비교 : mount unshare 시 부모 프로세스의 마운트 정보를 복사해서 자식 네임스페이스를 생성하여 처음은 동일
df -h
-----------------------
# [터미널2]
df -h
# [터미널1]
-----------------------
#
mkdir new_root
mount -t tmpfs none new_root
ls -l
tree new_root
## 마운트 정보 비교 : 마운트 네임스페이스를 unshare
df -h
mount | grep new_root
findmnt -A
## 파일 복사 후 터미널2 호스트와 비교
cp -r myroot/* new_root/
tree new_root/
-----------------------
# [터미널2]
cd /tmp
ls -l
tree new_root
df -h
mount | grep new_root
findmnt -A
## 안보이는 이유 : 마운트 네임스페이스를 unshare 된 상태
tree new_root/# 터미널1
-----------------------
mkdir new_root/put_old
## pivot_root 실행
cd new_root # pivot_root 는 실행 시, 변경될 root 파일시스템 경로로 진입
pivot_root . put_old # [신규 루트] [기존 루트]
##
cd /
ls / # 터미널2와 비교
ls put_old
-----------------------
# 터미널2
ls /
탈옥 시도
# 터미널1
-----------------------
./escape_chroot
cd ../../../
ls /
exit
exit
-----------------------


# 터미널1
-----------------------
mkdir new_root/put_old
## pivot_root 실행
cd new_root # pivot_root 는 실행 시, 변경될 root 파일시스템 경로로 진입
pivot_root . put_old # [신규 루트] [기존 루트]
##
cd /
ls / # 터미널2와 비교
ls put_old
-----------------------
# 터미널2
ls /
탈옥 시도
# 터미널1
-----------------------
./escape_chroot
cd ../../../
ls /
exit
exit
-----------------------
pivot root 는 탈옥이 되지 않네요


- 네임스페이스와 관련된 프로세스의 특징
- 모든 프로세스들은 네임스페이스 타입별로 특정 네임스페이스에 속합니다
- Child 는 Parent 의 네임스페이스를 상속받습니다
- 프로세스는 네임스페이스 타입별로 일부는 호스트(root) 네임스페이스를 사용하고 일부는 컨테이너의 네임스페이스를 사용할 수 있습니다.
- mount 네임스페이스는 컨테이너의 것으로 격리하고, network 네임스페이스는 호스트 것을 사용
- Mount(파일시스템), Network(네트워크), PID(프로세스 id), User(계정), ipc(프로세스간 통신), Uts(Unix time sharing, 호스트네임), cgroup

- 실습 : 터미널 2개 모두 관리자 권한으로 진행
- 프로세스 별 네임스페이스 확인
# [터미널 1,2] 관리자
sudo su -
cd /tmp
# 네임스페이스 확인 방법 1 : 프로세스 별 네임스페이스 확인
ls -al /proc/$$/ns
lrwxrwxrwx 1 root root 0 Aug 25 13:45 cgroup -> 'cgroup:[4026531835]'
lrwxrwxrwx 1 root root 0 Aug 25 13:45 ipc -> 'ipc:[4026531839]'
lrwxrwxrwx 1 root root 0 Aug 25 13:45 mnt -> 'mnt:[4026531841]'
lrwxrwxrwx 1 root root 0 Aug 25 13:45 net -> 'net:[4026531840]'
lrwxrwxrwx 1 root root 0 Aug 25 13:45 pid -> 'pid:[4026531836]'
lrwxrwxrwx 1 root root 0 Aug 25 13:45 pid_for_children -> 'pid:[4026531836]'
lrwxrwxrwx 1 root root 0 Aug 25 13:45 time -> 'time:[4026531834]'
lrwxrwxrwx 1 root root 0 Aug 25 13:45 time_for_children -> 'time:[4026531834]'
lrwxrwxrwx 1 root root 0 Aug 25 13:45 user -> 'user:[4026531837]'
lrwxrwxrwx 1 root root 0 Aug 25 13:45 uts -> 'uts:[4026531838]'
## 특정 네임스페이스의 inode 값만 확인
readlink /proc/$$/ns/mnt
readlink /proc/$$/ns/net
# 네임스페이스 확인 방법 2 : lsns - List system namespaces
lsns -h
lsns -p 1
lsns -p $$
## -t 네임스페이스 타입 , -p 조회할 PID
## NPROCS : 해당 네임스페이스에 속해있는 프로세스 갯수
## PID : 해당 네임스페이스의 (최초) 주인 프로세스
lsns -t mnt -p 1
lsns -t mnt -p $$

1. 마운트 네임스페이스 MOUNT (mnt) Namespace : 2002년, 마운트 포인트 격리, 최초의 네임스페이스
- echo $$ - 링크
# PID 1과 현재 Shell 속한 프로세스의 MNT NS 정보 확인
lsns -t mnt -p 1
lsns -t mnt -p $$
# [터미널1] /tmp 디렉터리
# unshare -m [명령어] : -m 옵션을 주면 [명령어]를 mount namespace 를 isolation 하여 실행합니다
unshare -m # *[명령어]를 지정하지 않으면 환경변수 $SHELL 실행
-----------------------------------
# NPROCS 값과 PID 값의 의미 확인
lsns -p $$
NS TYPE NPROCS PID USER COMMAND
4026531834 time 112 1 root /sbin/init
4026531835 cgroup 112 1 root /sbin/init
4026531836 pid 112 1 root /sbin/init
4026531837 user 112 1 root /sbin/init
4026531838 uts 108 1 root /sbin/init
4026531839 ipc 112 1 root /sbin/init
4026531840 net 112 1 root /sbin/init
4026532206 mnt 2 5834 root -bash
# PID 1과 비교
lsns -p 1
# 빠져나오기
exit
-----------------------------------
- 호스트 경로를 직접 마운트 시 주의 사항 : 예를 들어 호스트 최상위 루트 디렉터리 (/) 마운트 시 보안상 어떤 문제가 있을까요?
2. UTS 네임스페이스 Namespace : 2006년, Unix Time Sharing (여러 사용자 작업 환경 제공하고자 서버 시분할 나눠쓰기), 호스트명, 도메인명 격리
# unshare -u [명령어]
# -u 옵션을 주면 [명령어]를 UTS namespace 를 isolation 하여 실행
# [터미널1] /tmp 디렉터리
unshare -u
-----------------------------------
lsns -p $$
lsns -p 1
## 기본은 부모 네임스페스의 호스트 네임을 상속
hostname
## 호스트 네임 변경
hostname KANS
## 아래 터미널2에서 hostname 비교
hostname
exit
-----------------------------------
# [터미널2] /tmp 디렉터리
hostname

3. IPC 네임스페이스 : 2006년, Inter-Process Communication 격리, 프로세스 간 통신 자원 분리 관리 - Shared Memory, Pipe, Message Queue 등
# [터미널1] /tmp 디렉터리
unshare -i
-----------------------------------
lsns -p $$
lsns -p 1
exit
------------------------------------ [추가 실습] 2개의 컨테이너 간 IPC 네임스페이스 공유
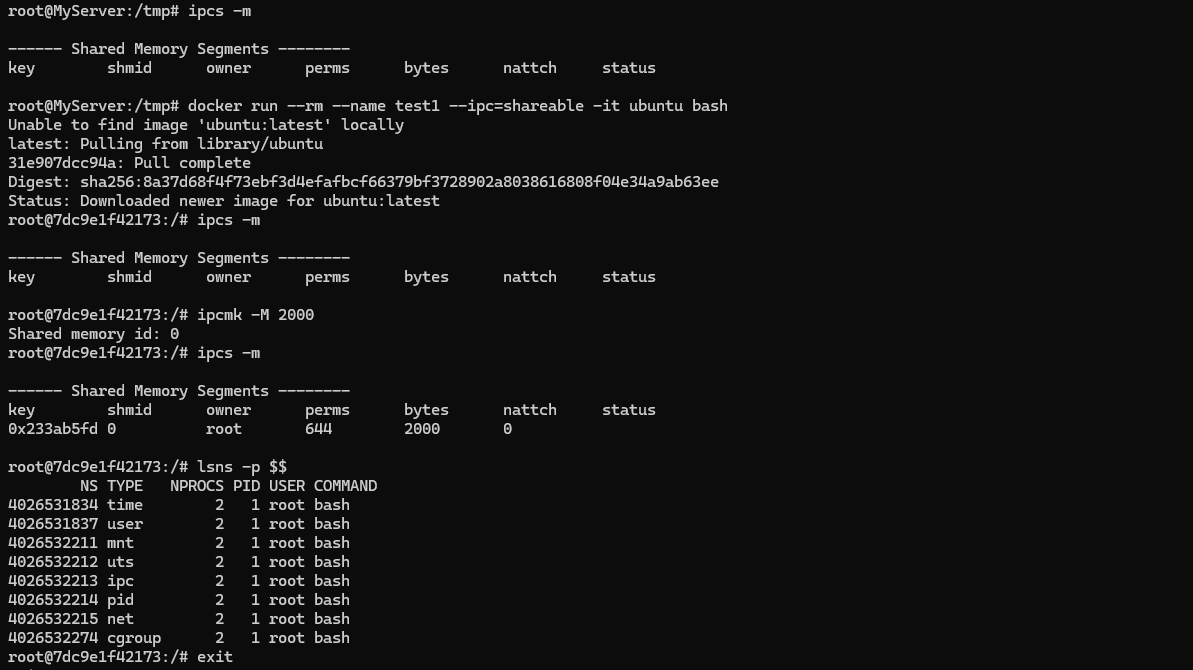

컨테이너간 ipc namespace 공유로 아래 내용 실행 가능함 확인
4. PID 네임스페이스 : 2008년, Process ID 격리
- 부모-자식 네임스페이스 중첩 구조, 부모 네임스페이스 에서는 → 자식 네임스페이스를 볼 수 있음
- 자식 네임스페이스는 parent tree 의 id 와 subtree 의 id 두 개를 가짐


ps -ef | head -n 3
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 09:57 ? 00:00:04 /sbin/init
root 2 0 0 09:57 ? 00:00:00 [kthreadd]- unshare 할 때 fork 하여, 자식 PID 네임스페이스의 pid 1로 실행
- pid 1 (init) 이 종료되면 pid namespace 도 종료


# unshare -p [명령어]
## -p 옵션을 주면 [명령어]를 PID namespace 를 isolation 하여 실행합니다
## -f(fork) : PID namespace 는 child 를 fork 하여 새로운 네임스페이스로 격리함
## --mount-proc : namespace 안에서 ps 명령어를 사용하려면 /proc 를 mount 하기위함
# [터미널1] /proc 파일시스템 마운트
echo $$
unshare -fp --mount-proc /bin/sh
--------------------------------
# 터미널2 호스트와 비교
echo $$
ps -ef
ps aux
# 내부에서 PID NS 확인 : 아래 터미널2에서 lsns -t pid -p <위 출력된 PID>와 비교
lsns -t pid -p 1
--------------------------------
# [터미널2]
ps -ef
ps aux
ps aux | grep '/bin/sh'
root 6186 0.0 0.0 6192 1792 pts/2 S 15:08 0:00 unshare -fp --mount-proc /bin/sh
root 6187 0.0 0.0 2892 1664 pts/2 S+ 15:08 0:00 /bin/sh
# 터미널1 PID NS와 비교
lsns -t pid -p <위 출력된 PID>
lsns -t pid -p 6187


- 호스트에서 컨테이너 프로세스 종료 해보기
# [터미널1]
--------------------------------
# fork
sleep 10000
# 아래 종료로 자동으로 sleep 가 exit 됨
echo $$
# 아래 종료로 자동으로 exit됨 : 컨테이너의 PID 1 프로세스 종료 시
--------------------------------
echo $$
# [터미널2]
ps aux | grep sleep
## 호스트에서 sleep 종료 시켜보기 : 어떻게 되는가?
kill -l
kill -SIGKILL $(pgrep sleep)
## 호스트에서 /bin/sh 종료 시켜보기 : 어떻게 되는가?
ps aux | grep '/bin/sh'
kill -SIGKILL <위 출력된 PID>
kill -9 6187


terminal2 에서 kill 명령으로 프로세스 실행이 종료됨
# Exit code 125 indicates that the error is with Docker daemon itself.
docker run --foo busybox; echo $?
flag provided but not defined: --foo
See 'docker run --help'.
125
# Exit code 126 indicates that the specified contained command can't be invoked.
# The container command in the following example is: /etc; echo $?.
docker run busybox /etc; echo $?
docker: Error response from daemon: Container command '/etc' could not be invoked.
126
# Exit code 127 indicates that the contained command can't be found.
docker run busybox foo; echo $?
docker: Error response from daemon: Container command 'foo' not found or does not exist.
127
# Other exit codes : Any exit code other than 125, 126, and 127 represent the exit code of the provided container command.
docker run busybox /bin/sh -c 'exit 3'
echo $?
3
docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
f02d387b3c00 busybox "/bin/sh -c 'exit 3'" 8 seconds ago Exited (3) 6 seconds ago youthful_hypatia
...
# 컨테이너 삭제
docker rm -f $(docker ps -aq)

5. 네트워크 네임스페이스 : 별도 설명, 2009년
6. USER 네임스페이스 : 2012년, UID/GID 넘버스페이스 격리(Remap_, 컨테이너의 루트권한 문제를 해결함, 부모-자식 네임스페이스의 중첩 구조

- 네임스페이스 안과 밖의 UID/GID 를 다르게 설정할 수 있음
- 사전 준비 : 터미널1(ubuntu 일반 유저, docker 실행 가능 상태) , 터미널2(ubuntu 일반 유저)
# 터미널1,2
exit
whoami
# 터미널1
docker run -it ubuntu /bin/sh
-----------------------------
# 아래 터미널2와 비교
whoami
id
# 아래 터미널2와 비교
ps -ef
# User 네임스페이스는 도커 컨테이너 실행 시, 호스트 User 를 그대로 사용
readlink /proc/$$/ns/user
lsns -p $$
NS TYPE NPROCS PID USER COMMAND
4026531834 time 2 1 root /bin/sh
4026531837 user 2 1 root /bin/sh
4026532208 mnt 2 1 root /bin/sh
4026532209 uts 2 1 root /bin/sh
4026532210 ipc 2 1 root /bin/sh
4026532211 pid 2 1 root /bin/sh
4026532212 net 2 1 root /bin/sh
4026532273 cgroup 2 1 root /bin/sh
# 아래 동작 확인 후 종료
exit
-----------------------------
# 터미널2
whoami
id
## root 로 실행됨
ps -ef |grep "/bin/sh"
ubuntu 6733 5348 0 15:34 pts/0 00:00:00 docker run -it ubuntu /bin/sh
root 6790 6768 0 15:34 pts/0 00:00:00 /bin/sh
##
readlink /proc/$$/ns/user
lsns -p $$
lsns -p $$ -t user
NS TYPE NPROCS PID USER COMMAND
4026531837 user 5 2391 ubuntu /lib/systemd/systemd --user- 컨테이너를 탈취 후, 해당 프로세스를 기반으로 호스트에 Action 이 가능할 경우, root 계정 권한 실행이 가능 ⇒ 보안상 취약
- 도커의 root 사용
- 패키지 인스톨이 쉽다
- 시스템리소스 이용에 제약이 없다
- But, 보안에 취약
- USER 네임스페이스 격리
- unshare -U --map-root-user /bin/sh
- USER 네임스페이스
- 컨테이너 안에서만 root
- USER 네임스페이스간 UID/GID Remap
- 도커의 USER 네임스페이스 지원
- 도커 v1.10+
- 호스트 UID/GID Remap
- 보안관점에서 큰 진보
- But, 기본설정은 USER 네임스페이스를 쓰지 않음
- 도커의 root 사용
# 터미널1
unshare -U --map-root-user /bin/sh
-----------------------------
# 내부에서는 여전히 root로 보임
whoami
id
# User 네임스페이스를 호스터(터미널2)와 비교
readlink /proc/$$/ns/user
lsns -p $$
# 아래 동작 확인 후 종료
exit
-----------------------------
# 터미널2
readlink /proc/$$/ns/user
lsns -p $$
## ubuntu 로 실행됨
ps -ef |grep "/bin/sh"
ubuntu 6874 5348 0 15:42 pts/0 00:00:00 /bin/sh





- 프로세스는 실행 중인 프로그램의 인스턴스를 의미. OS에서 프로세스를 관리하며, 각 프로세스는 고유한 ID(PID)를 가짐.
- 프로세스는 CPU와 메모리를 사용하는 기본 단위로, OS 커널(cgroup)에서 각 프로세스의 자원을 관리함.
- cgroups : Blog1 , Blog2
- cgroup v1, v2 : Blog1 , Blog2 , check
- cgroup v1, v2가 존재하며 v2는 v1에 비해 자원계층구조의 가시성을 향상.
- cgroup v1에서는 request, limit 두개의 자원설정만이 가능했는데, cgroup v2에서는 memoryQoS라는 기능을 추가하여 컨테이너 등에서 쉽사리 OOM이 나지않게 하는 기능 지원 → Memory High : 메모리 사용량 조절 제한. cgroup의 사용량이 높은 경계를 초과하면 cgroup의 프로세스가 제한되고 회수 압력이 커짐
- control groups : 프로세스들의 자원의 사용(CPU, 메모리, 디스크 입출력, 네트워크 등)을 제한, 격리시키는 리눅스 커널 기능 - Link
- 하나 또는 복수의 장치를 묶어서 하나의 그룹을 만들 수 있으며 개별 그룹은 시스템에서 설정한 값만큼 하드웨어를 사용
- 시스템의 프로세스들은 장치별로 특정한 cgroup에 속하여 프로세스가 사용하는 하드웨어 자원의 총량에 제한을 받음
- process를 계층적인 group으로 구성해서, resource 사용을 제한하고 모니터링할 수 있는 linux kernel feature
- cgroup의 interface는 cgroupfs이라 불리는 pseudo-filesystem을 통해 제공됨
- cgroupfs의 subdirectory를 생성/삭제/변경하면서 정의됨
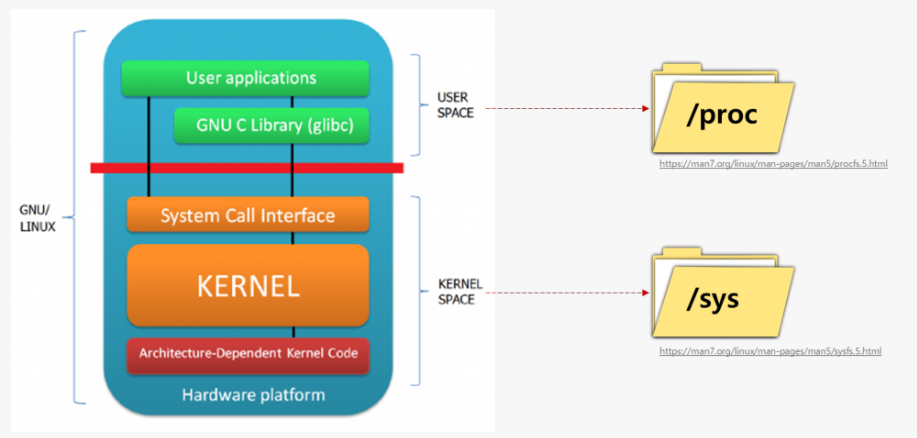
- /proc 와 /sys
- Runtime의 메모리 정보를 파일시스템 폴더에 mount한 pseudo-filesystem
- 커널 2.x 버전까지는 /proc 폴더 하나만 있었지만, 3.x 버전 부터 /sys를 추가로 구분하였음
- /proc, /sys 는 커널이 관리하는 메모리를 마운트했기 때문에 해당 디렉토리에 접근하는 순간 메모리에서 정보를 읽어 오게 됨
#
mount -t cgroup
mount -t cgroup2
cgroup2 on /sys/fs/cgroup type cgroup2 (rw,nosuid,nodev,noexec,relatime,nsdelegate,memory_recursiveprot)
#
findmnt -t cgroup2
TARGET SOURCE FSTYPE OPTIONS
/sys/fs/cgroup cgroup2 cgroup2 rw,nosuid,nodev,noexec,relatime,nsdelegate,memory_recursiveprot
# cgroup2 이외에 proc, bpf 도 있음
findmnt -A
TARGET SOURCE FSTYPE OPTIONS
/ /dev/nvme0n1p1 ext4 rw,relatime,discard,errors=remount-ro
...
├─/proc proc proc rw,nosuid,nodev,noexec,relatime
...
├─/sys sysfs sysfs rw,nosuid,nodev,noexec,relatime
│ ├─/sys/kernel/security securityfs securityfs rw,nosuid,nodev,noexec,relatime
│ ├─/sys/fs/cgroup cgroup2 cgroup2 rw,nosuid,nodev,noexec,relatime,nsdelegate,memory_recursiveprot
│ ├─/sys/fs/pstore pstore pstore rw,nosuid,nodev,noexec,relatime
│ ├─/sys/firmware/efi/efivars efivarfs efivarfs rw,nosuid,nodev,noexec,relatime
│ ├─/sys/fs/bpf bpf bpf rw,nosuid,nodev,noexec,relatime,mode=700
...
# cgroupv1 만 지원 시, cgroup2 출력되지 않음
grep cgroup /proc/filesystems
nodev cgroup
nodev cgroup2
stat -fc %T /sys/fs/cgroup/
cgroup2fs
# 터미널2
sleep 100000
# /proc에 cgroup 정보 확인
cat /proc/cgroups
cat /proc/$(pgrep sleep)/cgroup
0::/user.slice/user-1000.slice/session-7.scope
tree /proc/$(pgrep sleep) -L 2
...
├── ns
│ ├── cgroup -> cgroup:[4026531835]
│ ├── ipc -> ipc:[4026531839]
│ ├── mnt -> mnt:[4026531841]
│ ├── net -> net:[4026531840]
...
# cgroup 목록 확인
ls /sys/fs/cgroup
cat /sys/fs/cgroup/cgroup.controllers
#
tree /sys/fs/cgroup/ -L 1
tree /sys/fs/cgroup/ -L 2
tree /sys/fs/cgroup/user.slice -L 1
tree /sys/fs/cgroup/user.slice/user-1000.slice -L 1
tree /sys/fs/cgroup/user.slice/user-1000.slice -L 2
# 터미널1,2 관리자로 실습 진행
sudo su -
whoami
# 툴 설치
apt install cgroup-tools stress -y
# 터미널2 : 아래 stress 실행 후 CPU 사용률 확인
htop
# 터미널1에서 실습 진행
# 먼저 부하 발생 확인
stress -c 1
# 디렉터리 이동
cd /sys/fs/cgroup
# 서브 디렉터리 생성 후 확인 확인
mkdir test_cgroup_parent && cd test_cgroup_parent
tree
# 제어 가능 항목 확인
cat cgroup.controllers
# cpu를 subtree이 추가하여 컨트롤 할 수 있도록 설정 : +/-(추가/삭제)
cat cgroup.subtree_control
echo "+cpu" >> /sys/fs/cgroup/test_cgroup_parent/cgroup.subtree_control
# cpu.max 제한 설정 : 첫 번쨰 값은 허용된 시간(마이크로초) 두 번째 값은 총 기간 길이 > 1/10 실행 설정
echo 100000 1000000 > /sys/fs/cgroup/test_cgroup_parent/cpu.max
# test용 자식 디렉토리를 생성하고, pid를 추가하여 제한을 걸어
mkdir test_cgroup_child && cd test_cgroup_child
echo $$ > /sys/fs/cgroup/test_cgroup_parent/test_cgroup_child/cgroup.procs
cat /sys/fs/cgroup/test_cgroup_parent/test_cgroup_child/cgroup.procs
cat /proc/$$/cgroup
# 부하 발생 확인 : 터미널2에 htop 확인
stress -c 1
# 값 수정
echo 1000000 1000000 > /sys/fs/cgroup/test_cgroup_parent/cpu.max
# 부하 발생 확인 : 터미널2에 htop 확인
stress -c 1
# cgroup 삭제
exit
sudo su -
rmdir /sys/fs/cgroup/test_cgroup_parent/test_cgroup_child
rmdir /sys/fs/cgroup/test_cgroup_parent
# 아래는 cgroup v1 경우
---------------------------
## 1. 제어그룹 생성 : mycgroup
### -a : owner 설정 (control group's file)
### -g : cgroup 설정 <controllers>:<path>
### -g cpu:mycgroup ~ cpu controller 를 사용하고 path 는 mycgroup
cgcreate -a root -g cpu:mycgroup
tree /sys/fs/cgroup/cpu/mycgroup
## 2. 제어그룹 리소스 설정 : CPU 사용률 설정
### cpu 사용률(%CPU)
### cpu.cfs_quota_us / cat cpu.cfs_period_us * 100
### 참고 1000us = 1ms
### cpu사용률(30%)을 설정 (30,000/100,000)x100=30%
cgset -r cpu.cfs_quota_us=30000 mycgroup
cat /sys/fs/cgroup/cpu/mycgroup/cpu.cfs_quota_us
## 3. 제어그룹 프로세스 할당 : stress 실행
cgexec -g cpu:mycgroup stress -c 1
- ‘docker run —cpus’ 시 실제 값 확인 : https://p1p2.tistory.com/1
docker run --cpus=0.500 -ti --rm stress stress -c 1
cat original.output | grep -E "cpu.max$" -a1
./cpu.max
max 100000
cat cpus.output | grep -E "cpu.max$" -a1
./cpu.max
50000 100000
- 마무리
