
티스토리 뷰
CloudNet@ 가시다님이 진행하는 AWS EKS Hands-on Study 내용 참고.
5. 프로메테우스-스택
Prometheus: The Documentary
☞ 소개 : Prometheus is an open-source systems monitoring and alerting toolkit originally built at SoundCloud
제공 기능
- 메트릭 이름과 키/값 쌍으로 식별되는 시계열 데이터(=TSDB, 시계열 데이터베이스)를 활용한 다차원 데이터 모델
- 이 차원성을 활용할 수 있는 유연한 쿼리 언어인 PromQL
- 분산 스토리지에 의존하지 않으며, 단일 서버 노드는 독립적으로 운영됨 - Docs
- 시계열 데이터 수집은 HTTP를 통한 Pull 모델 방식으로 이루어짐 - Q&A ⇒ 질문: Push와 Pull 수집 방식의 장단점?
- 시계열 데이터 Push 방식도 중간 게이트웨이(intermediary gateway)를 통해 지원됨
- 대상(Target)은 서비스 디스커버리(service discovery) 또는 정적 설정(static configuration) 을 통해 발견됨
- 다양한 그래프 및 대시보드 모드 지원

구성 요소
- the main Prometheus server which scrapes and stores time series data
- client libraries for instrumenting application code
- a push gateway for supporting short-lived jobs
- special-purpose exporters for services like HAProxy, StatsD, Graphite, etc.
- an alertmanager to handle alerts
- various support tools
Metrics?
- 메트릭은 일반인이 이해하기 쉬운 수치적 측정입니다. 시계열이라는 용어는 시간에 따른 변화를 기록하는 것을 말합니다. 사용자가 측정하고자 하는 것은 애플리케이션마다 다릅니다. 웹 서버의 경우 요청 시간이 될 수 있고, 데이터베이스의 경우 활성 연결 또는 활성 쿼리 수가 될 수 있습니다.

☞ [운영서버 EC2] 프로메테우스 직접 설치 - Docs
- prometheus 설치
# 최신 버전 다운로드
wget https://github.com/prometheus/prometheus/releases/download/v3.2.0/prometheus-3.2.0.linux-amd64.tar.gz
# 압축 해제
tar -xvf prometheus-3.2.0.linux-amd64.tar.gz
cd prometheus-3.2.0.linux-amd64
ls -l
#
mv prometheus /usr/local/bin/
mv promtool /usr/local/bin/
mkdir -p /etc/prometheus /var/lib/prometheus
mv prometheus.yml /etc/prometheus/
cat /etc/prometheus/prometheus.yml
#
useradd --no-create-home --shell /sbin/nologin prometheus
chown -R prometheus:prometheus /etc/prometheus /var/lib/prometheus
chown prometheus:prometheus /usr/local/bin/prometheus /usr/local/bin/promtool
#
tee /etc/systemd/system/prometheus.service > /dev/null <<EOF
[Unit]
Description=Prometheus
Wants=network-online.target
After=network-online.target
[Service]
User=prometheus
Group=prometheus
Type=simple
ExecStart=/usr/local/bin/prometheus \
--config.file=/etc/prometheus/prometheus.yml \
--storage.tsdb.path=/var/lib/prometheus \
--web.listen-address=0.0.0.0:9090
[Install]
WantedBy=multi-user.target
EOF
#
systemctl daemon-reload
systemctl enable --now prometheus
systemctl status prometheus
ss -tnlp
#
curl localhost:9090/metrics
echo -e "http://$(curl -s ipinfo.io/ip):9090"

- node_exporter 설치 - Github
# Node Exporter 최신 버전 다운로드
cd ~
wget https://github.com/prometheus/node_exporter/releases/download/v1.9.0/node_exporter-1.9.0.linux-amd64.tar.gz
tar xvfz node_exporter-1.9.0.linux-amd64.tar.gz
cd node_exporter-1.9.0.linux-amd64
cp node_exporter /usr/local/bin/
#
groupadd -f node_exporter
useradd -g node_exporter --no-create-home --shell /sbin/nologin node_exporter
chown node_exporter:node_exporter /usr/local/bin/node_exporter
#
tee /etc/systemd/system/node_exporter.service > /dev/null <<EOF
[Unit]
Description=Node Exporter
Documentation=https://prometheus.io/docs/guides/node-exporter/
Wants=network-online.target
After=network-online.target
[Service]
User=node_exporter
Group=node_exporter
Type=simple
Restart=on-failure
ExecStart=/usr/local/bin/node_exporter \
--web.listen-address=:9200
[Install]
WantedBy=multi-user.target
EOF
# 데몬 실행
systemctl daemon-reload
systemctl enable --now node_exporter
systemctl status node_exporter
ss -tnlp
#
curl localhost:9200/metrics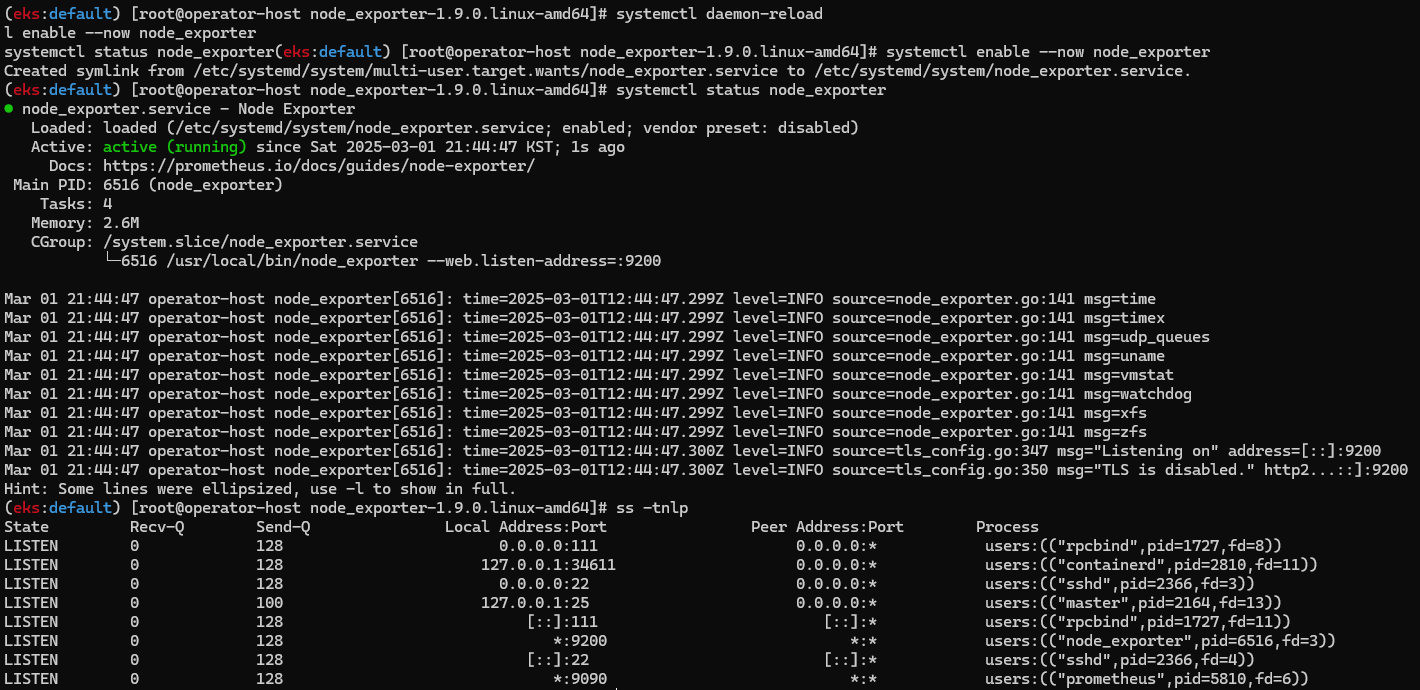

- prometheus 설정에 수집 대상 target (node_exporter) 추가
# prometheus.yml 수정
cat << EOF >> /etc/prometheus/prometheus.yml
- job_name: 'node_exporter'
static_configs:
- targets: ["127.0.0.1:9200"]
labels:
alias: 'myec2'
EOF
# prometheus 데몬 재기동
systemctl restart prometheus.service
systemctl status prometheus
- prometheus 웹에서 target 확인 및 node 로 시작되는 메트릭 쿼리 해보기
rate(node_cpu_seconds_total{mode="system"}[1m])
node_filesystem_avail_bytes
rate(node_network_receive_bytes_total[1m])

☞ 프로메테우스-스택 설치 : 모니터링에 필요한 여러 요소를 **단일 차트(스택)**으로 제공 ← 시각화(그라파나), 이벤트 메시지 정책(경고 임계값/수준) 등 - Helm
- kube-prometheus-stack은 Kubernetes 매니페스트, Grafana 대시보드, Prometheus 규칙을 문서 및 스크립트와 함께 수집하여, Prometheus Operator를 활용한 Kubernetes 클러스터의 엔드 투 엔드(end-to-end) 모니터링을 쉽게 운영할 수 있도록 제공하는 스택입니다.
# 모니터링
watch kubectl get pod,pvc,svc,ingress -n monitoring
# repo 추가
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
# 파라미터 파일 생성
cat <<EOT > monitor-values.yaml
prometheus:
prometheusSpec:
scrapeInterval: "15s"
evaluationInterval: "15s"
podMonitorSelectorNilUsesHelmValues: false
serviceMonitorSelectorNilUsesHelmValues: false
retention: 5d
retentionSize: "10GiB"
storageSpec:
volumeClaimTemplate:
spec:
storageClassName: gp3
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 30Gi
ingress:
enabled: true
ingressClassName: alb
hosts:
- prometheus.$MyDomain
paths:
- /*
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'
grafana:
defaultDashboardsTimezone: Asia/Seoul
adminPassword: prom-operator
ingress:
enabled: true
ingressClassName: alb
hosts:
- grafana.$MyDomain
paths:
- /*
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'
persistence:
enabled: true
type: sts
storageClassName: "gp3"
accessModes:
- ReadWriteOnce
size: 20Gi
alertmanager:
enabled: false
defaultRules:
create: false
kubeControllerManager:
enabled: false
kubeEtcd:
enabled: false
kubeScheduler:
enabled: false
prometheus-windows-exporter:
prometheus:
monitor:
enabled: false
EOT
cat monitor-values.yaml
# 배포
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack --version 69.3.1 \
-f monitor-values.yaml --create-namespace --namespace monitoring
# 확인
## alertmanager-0 : 사전에 정의한 정책 기반(예: 노드 다운, 파드 Pending 등)으로 시스템 경고 메시지를 생성 후 경보 채널(슬랙 등)로 전송
## grafana-0 : 프로메테우스는 메트릭 정보를 저장하는 용도로 사용하며, 그라파나로 시각화 처리
## prometheus-0 : 모니터링 대상이 되는 파드는 ‘exporter’라는 별도의 사이드카 형식의 파드에서 모니터링 메트릭을 노출, pull 방식으로 가져와 내부의 시계열 데이터베이스에 저장
## node-exporter : 노드익스포터는 물리 노드에 대한 자원 사용량(네트워크, 스토리지 등 전체) 정보를 메트릭 형태로 변경하여 노출
## operator : 시스템 경고 메시지 정책(prometheus rule), 애플리케이션 모니터링 대상 추가 등의 작업을 편리하게 할수 있게 CRD 지원
## kube-state-metrics : 쿠버네티스의 클러스터의 상태(kube-state)를 메트릭으로 변환하는 파드
helm list -n monitoring
kubectl get sts,ds,deploy,pod,svc,ep,ingress,pvc,pv -n monitoring
kubectl get-all -n monitoring
kubectl get prometheus,servicemonitors -n monitoring
kubectl get crd | grep monitoring
kubectl df-pv
# 프로메테우스 버전 확인
echo -e "https://prometheus.$MyDomain/api/v1/status/buildinfo"
open https://prometheus.$MyDomain/api/v1/status/buildinfo # macOS
kubectl exec -it sts/prometheus-kube-prometheus-stack-prometheus -n monitoring -c prometheus -- prometheus --version
prometheus, version 3.1.0 (branch: HEAD, revision: 7086161a93b262aa0949dbf2aba15a5a7b13e0a3)
...
# 프로메테우스 웹 접속
echo -e "https://prometheus.$MyDomain"
open "https://prometheus.$MyDomain" # macOS
# 그라파나 웹 접속
echo -e "https://grafana.$MyDomain"
open "https://grafana.$MyDomain" # macOS




- AWS ELB(ALB) 갯수 확인 → Rule 확인(어떻게 여러 도메인 처리를 하는 걸까?) ⇒ HTTP(80) 인입 시 어떻게 처리하나요?


- 프로메테우스 웹 → Status → Targets 확인 : kube-controller-manager, etcd, kube-scheduler 확인
- (참고) 삭제 시
# helm 삭제
helm uninstall -n monitoring kube-prometheus-stack
# crd 삭제
kubectl delete crd alertmanagerconfigs.monitoring.coreos.com
kubectl delete crd alertmanagers.monitoring.coreos.com
kubectl delete crd podmonitors.monitoring.coreos.com
kubectl delete crd probes.monitoring.coreos.com
kubectl delete crd prometheuses.monitoring.coreos.com
kubectl delete crd prometheusrules.monitoring.coreos.com
kubectl delete crd servicemonitors.monitoring.coreos.com
kubectl delete crd thanosrulers.monitoring.coreos.com
☞ [Amazon EKS] AWS CNI Metrics 수집을 위한 사전 설정 - 링크
# PodMonitor 배포
cat <<EOF | kubectl create -f -
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
name: aws-cni-metrics
namespace: kube-system
spec:
jobLabel: k8s-app
namespaceSelector:
matchNames:
- kube-system
podMetricsEndpoints:
- interval: 30s
path: /metrics
port: metrics
selector:
matchLabels:
k8s-app: aws-node
EOF
# PodMonitor 확인
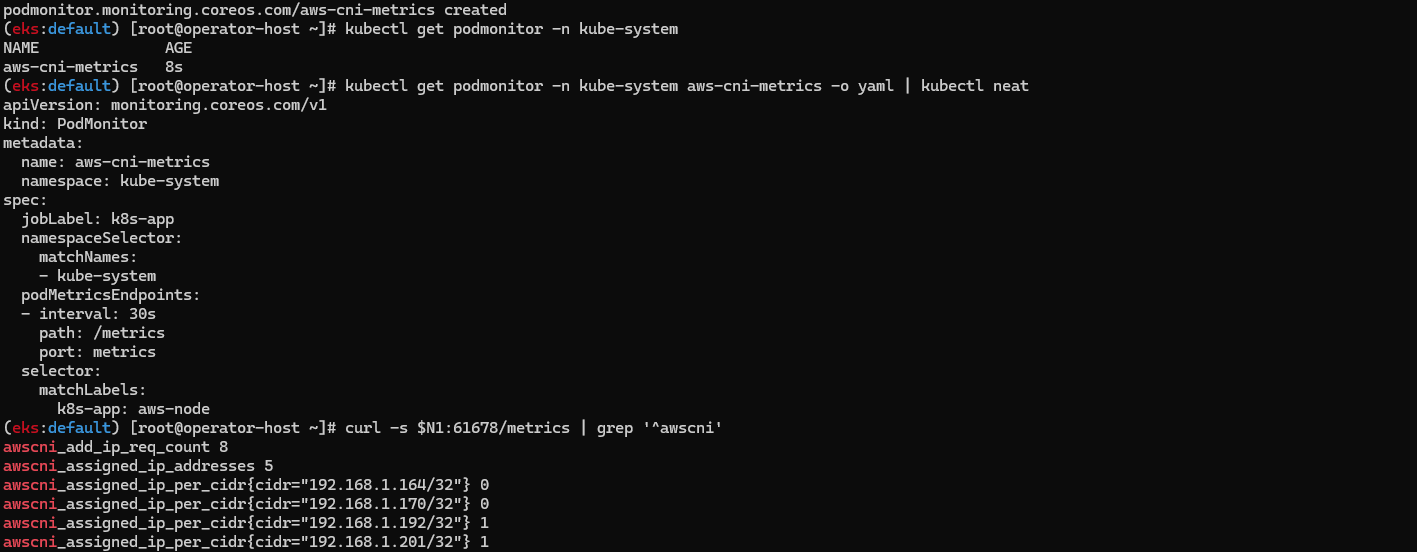
kubectl get podmonitor -n kube-system
kubectl get podmonitor -n kube-system aws-cni-metrics -o yaml | kubectl neat
# metrics url 접속 확인
curl -s $N1:61678/metrics | grep '^awscni'
awscni_add_ip_req_count 10
awscni_assigned_ip_addresses 8
awscni_assigned_ip_per_cidr{cidr="192.168.1.117/32"} 1
awscni_assigned_ip_per_cidr{cidr="192.168.1.131/32"} 1
awscni_assigned_ip_per_cidr{cidr="192.168.1.184/32"} 1
awscni_assigned_ip_per_cidr{cidr="192.168.1.210/32"} 0
awscni_assigned_ip_per_cidr{cidr="192.168.1.243/32"} 1
awscni_assigned_ip_per_cidr{cidr="192.168.1.247/32"} 1
awscni_assigned_ip_per_cidr{cidr="192.168.1.38/32"} 1
...
- 프로메테우스 Target , job (aws-cni 검색)

ServiceMonitor vs PodMonitor 은 어떤 차이가 있을까?
https://github.com/prometheus-operator/prometheus-operator/issues/3119
- ServiceMonitor
- Service가 존재하는 경우 사용.
- 여러 개의 Pod를 라운드 로빈 방식으로 접근 가능.
- 대표적인 사용 사례: 애플리케이션 메트릭 수집 (nginx, redis, fluent-bit 등).
- PodMonitor
- 서비스 없이 직접 Pod에서 수집해야 하는 경우 사용.
- DaemonSet과 같이 노드 단위로 실행되는 애플리케이션에 적합.
- 대표적인 사용 사례: node-exporter, kubelet, cAdvisor 등 Kubernetes 노드 메트릭 수집.
즉, ServiceMonitor는 서비스 기반, PodMonitor는 Pod 기반으로 데이터를 수집하는 방식의 차이가 있다! (by chatgpt)
☞ 프로메테우스 기본 사용 : 모니터링 그래프
- 모니터링 대상이 되는 서비스는 일반적으로 자체 웹 서버의 /metrics 엔드포인트 경로에 다양한 메트릭 정보를 노출
- 이후 프로메테우스는 해당 경로에 http get 방식으로 메트릭 정보를 가져와 TSDB 형식으로 저장
# 아래 처럼 프로메테우스가 각 서비스의 포트 접속하여 메트릭 정보를 수집
kubectl get node -owide
kubectl get svc,ep -n monitoring kube-prometheus-stack-prometheus-node-exporter
# (노드 익스포터 경우) 노드의 9100번 포트의 /metrics 접속 시 다양한 메트릭 정보를 확인할수 있음 : 마스터 이외에 워커노드도 확인 가능
ssh ec2-user@$N1 curl -s localhost:9100/metrics
- 프로메테우스 ingress 도메인으로 웹 접속
# ingress 확인
kubectl get ingress -n monitoring kube-prometheus-stack-prometheus
kubectl describe ingress -n monitoring kube-prometheus-stack-prometheus
# 프로메테우스 ingress 도메인으로 웹 접속
echo -e "Prometheus Web URL = https://prometheus.$MyDomain"
open "https://prometheus.$MyDomain" macOS
# 웹 상단 주요 메뉴 설명
1. 쿼리(Query) : 프로메테우스 자체 검색 언어 PromQL을 이용하여 메트릭 정보를 조회 -> 단순한 그래프 형태 조회
2. 경고(Alerts) : 사전에 정의한 시스템 경고 정책(Prometheus Rules)에 대한 상황
3. 상태(Status) : 경고 메시지 정책(Rules), 모니터링 대상(Targets) 등 다양한 프로메테우스 설정 내역을 확인 > 버전 조정
- 쿼리 입력 옵션

- Use local time : 출력 시간을 로컬 타임으로 변경
- Enable query history : PromQL 쿼리 히스토리 활성화
- Enable autocomplete : 자동 완성 기능 활성화
- Enable highlighting : 하이라이팅 기능 활성화
- Enable linter : 문법 오류 감지, 자동 코스 스타일 체크
- Statues → 프로메테우스 설정(Configuration) 확인 : Status → Runtime & Build Information 클릭
- Storage retention : 5d or 10GiB → 메트릭 저장 기간이 5일 경과 혹은 10GiB 이상 시 오래된 것부터 삭제 ⇒ helm 파라미터에서 수정 가능
- Statues → 프로메테우스 설정(Configuration) 확인 : Status → Command-Line Flags 클릭
- -log.level : info
- -storage.tsdb.retention.size : 10GiB
- -storage.tsdb.retention.time : 5d
- Statues → 프로메테우스 설정(Configuration) 확인 : Status → Configuration

- job name 을 기준으로 scraping
global:
scrape_interval: 15s # 메트릭 가져오는(scrape) 주기
scrape_timeout: 10s # 메트릭 가져오는(scrape) 타임아웃
evaluation_interval: 15s # alert 보낼지 말지 판단하는 주기
...
- job_name: serviceMonitor/monitoring/kube-prometheus-stack-prometheus-node-exporter/0
scrape_interval: 30s
scrape_timeout: 10s
metrics_path: /metrics
scheme: http
...
relabel_configs:
- source_labels: [job]
separator: ;
target_label: __tmp_prometheus_job_name
replacement: $1
action: replace
- source_labels: [__meta_kubernetes_service_label_app_kubernetes_io_instance, __meta_kubernetes_service_labelpresent_app_kubernetes_io_instance]
separator: ;
regex: (kube-prometheus-stack);true
replacement: $1
action: keep
- source_labels: [__meta_kubernetes_service_label_app_kubernetes_io_name, __meta_kubernetes_service_labelpresent_app_kubernetes_io_name]
separator: ;
regex: (prometheus-node-exporter);true
replacement: $1
action: keep
...
kubernetes_sd_configs: # 서비스 디스커버리(SD) 방식을 이용하고, 파드의 엔드포인트 List 자동 반영
- role: endpoints # 서비스에 연결된 엔드포인트(Pod IP + Port) 탐색
kubeconfig_file: "" # Prometheus가 실행 중인 환경의 기본 kubeconfig 사용
follow_redirects: true # 엔드포인트를 변경할 경우 이를 따라감
enable_http2: true
namespaces:
own_namespace: false # 자신이 실행 중인 네임스페이스가 아닌 곳에서도 탐색 가능
names:
- monitoring # 서비스 엔드포인트가 속한 네임 스페이스 이름을 지정 : monitoring 네임스페이스에 있는 서비스만 타겟팅, 서비스 네임스페이스가 속한 포트 번호를 구분하여 메트릭 정보를 가져옴
...
- job_name: podMonitor/kube-system/aws-cni-metrics/0
honor_timestamps: true
...
relabel_configs:
- source_labels: [job]
separator: ;
target_label: __tmp_prometheus_job_name
replacement: $1
action: replace # job 라벨 값을 __tmp_prometheus_job_name에 저장
- source_labels: [__meta_kubernetes_pod_label_k8s_app, __meta_kubernetes_pod_labelpresent_k8s_app]
separator: ;
regex: (aws-node);true
replacement: $1
action: keep # Pod의 k8s_app 라벨 값이 aws-node인 경우만 유지
...
kubernetes_sd_configs:
- role: pod # 클러스터 내 모든 개별 Pod 탐색
kubeconfig_file: ""
follow_redirects: true
enable_http2: true
namespaces:
own_namespace: false
names:
- kube-system
...
- 전체 메트릭 대상(Targets) 확인 : Status → Target health
- 해당 스택은 ‘노드-익스포터’, cAdvisor, 쿠버네티스 전반적인 현황 이외에 다양한 메트릭을 포함
- 현재 각 Target 클릭 시 메트릭 정보 확인 : 아래 예시
# serviceMonitor/monitoring/kube-prometheus-stack-kube-proxy/0 (3/3 up) 중 노드1에 Endpoint 접속 확인 (접속 주소는 실습 환경에 따라 다름)
ssh ec2-user@$N1 curl -s http://localhost:10249/metrics
rest_client_response_size_bytes_bucket{host="006fc3f3f0730a7fb3fdb3181f546281.gr7.ap-northeast-2.eks.amazonaws.com",verb="POST",le="4.194304e+06"} 1
rest_client_response_size_bytes_bucket{host="006fc3f3f0730a7fb3fdb3181f546281.gr7.ap-northeast-2.eks.amazonaws.com",verb="POST",le="1.6777216e+07"} 1
rest_client_response_size_bytes_bucket{host="006fc3f3f0730a7fb3fdb3181f546281.gr7.ap-northeast-2.eks.amazonaws.com",verb="POST",le="+Inf"} 1
rest_client_response_size_bytes_sum{host="006fc3f3f0730a7fb3fdb3181f546281.gr7.ap-northeast-2.eks.amazonaws.com",verb="POST"} 626
rest_client_response_size_bytes_count{host="006fc3f3f0730a7fb3fdb3181f546281.gr7.ap-northeast-2.eks.amazonaws.com",verb="POST"} 1
...
# [운영서버 EC2] serviceMonitor/monitoring/kube-prometheus-stack-api-server/0 (2/2 up) 중 Endpoint 접속 확인 (접속 주소는 실습 환경에 따라 다름)
>> 해당 IP주소는 어디인가요?, 왜 apiserver endpoint는 2개뿐인가요? , 아래 메트릭 수집이 되게 하기 위해서는 어떻게 하면 될까요?
curl -s https://192.168.1.7/metrics | tail -n 5
...
# [운영서버 EC2] 그외 다른 타켓의 Endpoint 로 접속 확인 가능 : 예시) 아래는 coredns 의 Endpoint 주소 (접속 주소는 실습 환경에 따라 다름)
curl -s http://192.168.1.4:9153/metrics | tail -n 5
# TYPE process_virtual_memory_bytes gauge
process_virtual_memory_bytes 7.79350016e+08
# HELP process_virtual_memory_max_bytes Maximum amount of virtual memory available in bytes.
# TYPE process_virtual_memory_max_bytes gauge
process_virtual_memory_max_bytes 1.8446744073709552e+19
- 프로메테우스 설정(Configuration) 확인 : Status → Service Discovery : 모든 endpoint 로 도달 가능 시 자동 발견!, 도달 규칙은 설정Configuration 파일에 정의
- 예) serviceMonitor/monitoring/kube-prometheus-stack-apiserver/0 경우 해당 address="192.168.1.53:443" 도달 가능 시 자동 발견됨
- 메트릭을 그래프(Graph)로 조회 : Graph - 아래 PromQL 쿼리(전체 클러스터 노드의 CPU 사용량 합계)입력 후 조회 → Graph 확인
- 혹은 지구 아이콘(Metrics Explorer) 클릭 시 전체 메트릭 출력되며, 해당 메트릭 클릭해서 확인
node_cpu_seconds_total
node_cpu_seconds_total{mode="idle"}
(node_cpu_seconds_total{mode="idle"}[1m])# 노드 메트릭
node 입력 후 자동 출력되는 메트릭 확인 후 선택
node_boot_time_seconds
# kube 메트릭
kube 입력 후 자동 출력되는 메트릭 확인 후 선택
☞ [중급] 쿼리 : node-exporter , kube-state-metrics , kube-proxy
# Table 아래 쿼리 입력 후 Execute 클릭 -> Graph 확인
## 출력되는 메트릭 정보는 node-exporter 를 통해서 노드에서 수집된 정보
node_memory_Active_bytes
# 특정 노드(인스턴스) 필터링 : 아래 IP는 출력되는 자신의 인스턴스 PrivateIP 입력 후 Execute 클릭 -> Graph 확인
node_memory_Active_bytes{instance="192.168.1.105:9100"}
- kube-state-metrics (ksm) : k8s api 통해 k8s 오브젝트 정보 수집 - Link

# replicas's number
kube_deployment_status_replicas
kube_deployment_status_replicas_available
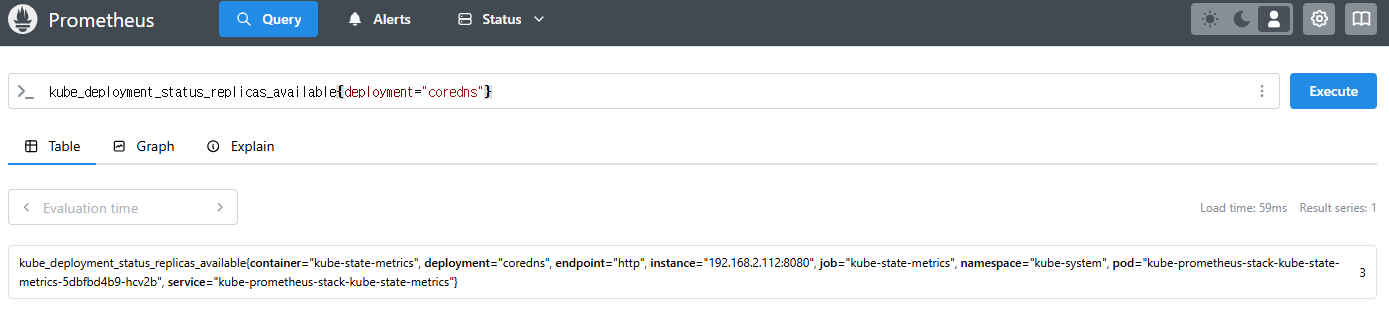
kube_deployment_status_replicas_available{deployment="coredns"}
# scale out
kubectl scale deployment -n kube-system coredns --replicas 3
# 확인
kube_deployment_status_replicas_available{deployment="coredns"}
# scale in
kubectl scale deployment -n kube-system coredns --replicas 1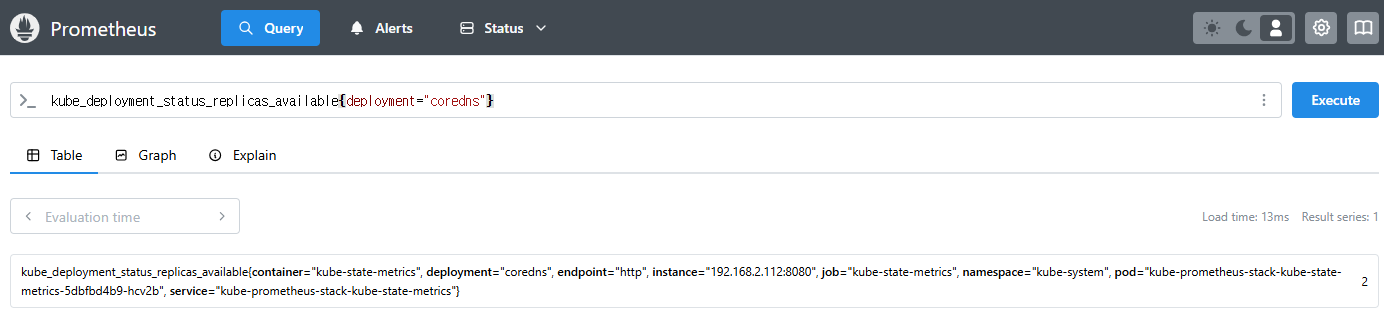
- kube-proxy : Github → 이미 애플리케이션 내장으로 메트릭 노출 준비 설정됨! (아래 코드 설명 by ChatGPT) → coredns 도? https://coredns.io/plugins/metrics/
- Kubernetes의 kube-proxy에서 사용되는 성능 및 상태 모니터링을 위한 메트릭을 정의하는 코드이다.
- iptables, IPVS, NFTables 등 프록시 모드별로 적절한 메트릭을 등록 및 관리한다.
- Netfilter 기반의 패킷 통계(nfacct)도 지원하여 패킷 드롭 및 로컬 트래픽 모니터링 기능을 포함한다.
#
kubeproxy_sync_proxy_rules_iptables_total
kubeproxy_sync_proxy_rules_iptables_total{table="filter"}
kubeproxy_sync_proxy_rules_iptables_total{table="nat"}
kubeproxy_sync_proxy_rules_iptables_total{table="nat", instance="192.168.1.188:10249"}
☞ [중급] 쿼리 : 애플리케이션 - NGINX 웹서버 애플리케이션 모니터링 설정 및 접속
- 서비스모니터 동작

- nginx 를 helm 설치 시 프로메테우스 익스포터 Exporter 옵션 설정 시 자동으로 nginx 를 프로메테우스 모니터링에 등록 가능!
- 프로메테우스 설정에서 nginx 모니터링 관련 내용을 서비스 모니터 CRD로 추가 가능!
- 기존 애플리케이션 파드에 프로메테우스 모니터링을 추가하려면 사이드카 방식을 사용하며 exporter 컨테이너를 추가! - KrBlog

- nginx 웹 서버(with helm)에 metrics 수집 설정 추가 - Helm
# 모니터링
watch -d "kubectl get pod; echo; kubectl get servicemonitors -n monitoring"
# nginx 파드내에 컨테이너 갯수 확인
kubectl describe pod -l app.kubernetes.io/instance=nginx
# 파라미터 파일 생성 : 서비스 모니터 방식으로 nginx 모니터링 대상을 등록하고, export 는 9113 포트 사용
# The chart can deploy ServiceMonitor objects for integration with Prometheus Operator installations. To do so, set the value metrics.serviceMonitor.enabled=true.
cat <<EOT > nginx-values.yaml
metrics:
enabled: true
service:
port: 9113
serviceMonitor:
enabled: true
namespace: monitoring
interval: 10s
EOT
# 배포
helm upgrade nginx bitnami/nginx --reuse-values -f nginx-values.yaml
# 확인
kubectl get pod,svc,ep
kubectl get servicemonitor -n monitoring nginx
kubectl get servicemonitor -n monitoring nginx -o json | jq
kubectl get servicemonitor -n monitoring nginx -o yaml | kubectl neat
#
kubectl krew install view-secret
kubectl get secret -n monitoring
kubectl view-secret -n monitoring prometheus-kube-prometheus-stack-prometheus
kubectl view-secret -n monitoring prometheus-kube-prometheus-stack-prometheus | zcat | more
kubectl view-secret -n monitoring prometheus-kube-prometheus-stack-prometheus | zcat | grep nginx -A 20
# [운영서버 EC2] 메트릭 확인 >> 프로메테우스에서 Target 확인
## nginx sub_status url 접속해보기
NGINXIP=$(kubectl get pod -l app.kubernetes.io/instance=nginx -o jsonpath="{.items[0].status.podIP}")
curl -s http://$NGINXIP:9113/metrics # nginx_connections_active Y 값 확인해보기
curl -s http://$NGINXIP:9113/metrics | grep ^nginx_connections_active
# nginx 파드내에 컨테이너 갯수 확인 : metrics 컨테이너 확인
kubectl get pod -l app.kubernetes.io/instance=nginx
kubectl describe pod -l app.kubernetes.io/instance=nginx
# 접속 주소 확인 및 접속
echo -e "Nginx WebServer URL = https://nginx.$MyDomain"
curl -s https://nginx.$MyDomain
kubectl stern deploy/nginx
# 반복 접속
while true; do curl -s https://nginx.$MyDomain -I | head -n 1; date; sleep 1; done- 서비스 모니터링 생성 후 3분 정도 후에 프로메테우스 웹서버에서 State → Targets 에 nginx 서비스 모니터 추가 확인





- State → Configuration : nginx 검색 후 job 확인
(참고) job_name : serviceMonitor/monitoring/nginx/0
- job_name: serviceMonitor/monitoring/nginx/0
honor_timestamps: true
track_timestamps_staleness: false
scrape_interval: 10s
scrape_timeout: 10s
scrape_protocols:
- OpenMetricsText1.0.0
- OpenMetricsText0.0.1
- PrometheusText1.0.0
- PrometheusText0.0.4
metrics_path: /metrics
scheme: http
enable_compression: true
follow_redirects: true
enable_http2: true
relabel_configs:
- source_labels: [job]
separator: ;
target_label: __tmp_prometheus_job_name
replacement: $1
action: replace
- source_labels: [__meta_kubernetes_service_label_app_kubernetes_io_instance, __meta_kubernetes_service_labelpresent_app_kubernetes_io_instance]
separator: ;
regex: (nginx);true
replacement: $1
action: keep
- source_labels: [__meta_kubernetes_service_label_app_kubernetes_io_name, __meta_kubernetes_service_labelpresent_app_kubernetes_io_name]
separator: ;
regex: (nginx);true
replacement: $1
action: keep
- source_labels: [__meta_kubernetes_endpoint_port_name]
separator: ;
regex: metrics
replacement: $1
action: keep
- source_labels: [__meta_kubernetes_endpoint_address_target_kind, __meta_kubernetes_endpoint_address_target_name]
separator: ;
regex: Node;(.*)
target_label: node
replacement: ${1}
action: replace
- source_labels: [__meta_kubernetes_endpoint_address_target_kind, __meta_kubernetes_endpoint_address_target_name]
separator: ;
regex: Pod;(.*)
target_label: pod
replacement: ${1}
action: replace
- source_labels: [__meta_kubernetes_namespace]
separator: ;
target_label: namespace
replacement: $1
action: replace
- source_labels: [__meta_kubernetes_service_name]
separator: ;
target_label: service
replacement: $1
action: replace
- source_labels: [__meta_kubernetes_pod_name]
separator: ;
target_label: pod
replacement: $1
action: replace
- source_labels: [__meta_kubernetes_pod_container_name]
separator: ;
target_label: container
replacement: $1
action: replace
- source_labels: [__meta_kubernetes_pod_phase]
separator: ;
regex: (Failed|Succeeded)
replacement: $1
action: drop
- source_labels: [__meta_kubernetes_service_name]
separator: ;
target_label: job
replacement: ${1}
action: replace
- separator: ;
target_label: endpoint
replacement: metrics
action: replace
- source_labels: [__address__, __tmp_hash]
separator: ;
regex: (.+);
target_label: __tmp_hash
replacement: $1
action: replace
- source_labels: [__tmp_hash]
separator: ;
modulus: 1
target_label: __tmp_hash
replacement: $1
action: hashmod
- source_labels: [__tmp_hash]
separator: ;
regex: "0"
replacement: $1
action: keep
kubernetes_sd_configs:
- role: endpoints
kubeconfig_file: ""
follow_redirects: true
enable_http2: true
namespaces:
own_namespace: false
names:
- default-
- 설정이 자동으로 반영되는 원리 : 주요 config 적용 필요 시 reloader 동작!
#
kubectl describe pod -n monitoring prometheus-kube-prometheus-stack-prometheus-0
...
config-reloader:
Container ID: containerd://c498b14aef223c4988ada125771707a3a2a662bfe8dbe3619663f89dd24460d8
Image: quay.io/prometheus-operator/prometheus-config-reloader:v0.80.0
Image ID: quay.io/prometheus-operator/prometheus-config-reloader@sha256:9f8ffd1eb787120225ab11e8a6b59d92b716fadf5f50924a0a1f9e9f5b71508d
Port: 8080/TCP
Host Port: 0/TCP
Command:
/bin/prometheus-config-reloader
Args:
--listen-address=:8080
--reload-url=http://127.0.0.1:9090/-/reload
--config-file=/etc/prometheus/config/prometheus.yaml.gz
--config-envsubst-file=/etc/prometheus/config_out/prometheus.env.yaml
--watched-dir=/etc/prometheus/rules/prometheus-kube-prometheus-stack-prometheus-rulefiles-0
State: Running
Started: Sat, 01 Mar 2025 21:51:23 +0900
Ready: True
Restart Count: 0
Environment:
POD_NAME: prometheus-kube-prometheus-stack-prometheus-0 (v1:metadata.name)
SHARD: 0
Mounts:
/etc/prometheus/config from config (rw)
/etc/prometheus/config_out from config-out (rw)
/etc/prometheus/rules/prometheus-kube-prometheus-stack-prometheus-rulefiles-0 from prometheus-kube-prometheus-stack-prometheus-rulefiles-0 (rw)
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-mh7vt (ro)
...- 쿼리 : 애플리케이션, Graph → nginx_ 입력 시 다양한 메트릭 추가 확인 : nginx_connections_active 등
# nginx scale out : Targets 확인
kubectl scale deployment nginx --replicas 2
# 쿼리 Table -> Graph
nginx_up
sum(nginx_up)
nginx_http_requests_total
nginx_connections_active
- 프로메테우스 메트릭 종류 (4종) : Counter, Gauge, Histogram, Summary - Link Blog
- 게이지 Gauge : 특정 시점의 값을 표현하기 위해서 사용하는 메트릭 타입, CPU 온도나 메모리 사용량에 대한 현재 시점 값
- 카운터 Counter : 누적된 값을 표현하기 위해 사용하는 메트릭 타입, 증가 시 구간 별로 변화(추세) 확인, 계속 증가 → 함수 등으로 활용
- 서머리 Summary : 구간 내에 있는 메트릭 값의 빈도, 중앙값 등 통계적 메트릭
- 히스토그램 Histogram : 사전에 미리 정의한 구간 내에 있는 메트릭 값의 빈도를 측정 → 함수로 측정 포맷을 변경
- PromQL Query - Docs Operator Example
- Label Matchers : = , ! = , =~ 정규표현식
# 예시
node_memory_Active_bytes
node_memory_Active_bytes{instance="192.168.1.188:9100"}
node_memory_Active_bytes{instance!="192.168.1.188:9100"}
# 정규표현식
node_memory_Active_bytes{instance=~"192.168.+"}
node_memory_Active_bytes{instance=~"192.168.1.+"}
# 다수 대상
node_memory_Active_bytes{instance=~"192.168.1.10:9100|192.168.2.247:9100"}
node_memory_Active_bytes{instance!~"192.168.1.10:9100|192.168.2.247:9100"}
# 여러 조건 AND
kube_deployment_status_replicas_available{namespace="kube-system"}
kube_deployment_status_replicas_available{namespace="kube-system", deployment="coredns"}

- Binary Operators 이진 연산자 - Link
- 산술 이진 연산자 : + - * / * ^
- 비교 이진 연산자 : = = ! = > < > = < =
- 논리/집합 이진 연산자 : and 교집합 , or 합집합 , unless 차집합
# 산술 이진 연산자 : + - * / * ^
node_memory_Active_bytes
node_memory_Active_bytes/1024
node_memory_Active_bytes/1024/1024
# 비교 이진 연산자 : = = ! = > < > = < =
nginx_http_requests_total
nginx_http_requests_total > 100
nginx_http_requests_total > 10000
# 논리/집합 이진 연산자 : and 교집합 , or 합집합 , unless 차집합
kube_pod_status_ready
kube_pod_container_resource_requests
kube_pod_status_ready == 1
kube_pod_container_resource_requests > 1
kube_pod_status_ready == 1 or kube_pod_container_resource_requests > 1
kube_pod_status_ready == 1 and kube_pod_container_resource_requests > 1
- Aggregation Operators 집계 연산자 - Link
- sum (calculate sum over dimensions) : 조회된 값들을 모두 더함
- min (select minimum over dimensions) : 조회된 값에서 가장 작은 값을 선택
- max (select maximum over dimensions) : 조회된 값에서 가장 큰 값을 선택
- avg (calculate the average over dimensions) : 조회된 값들의 평균 값을 계산
- group (all values in the resulting vector are 1) : 조회된 값을 모두 ‘1’로 바꿔서 출력
- stddev (calculate population standard deviation over dimensions) : 조회된 값들의 모 표준 편차를 계산
- stdvar (calculate population standard variance over dimensions) : 조회된 값들의 모 표준 분산을 계산
- count (count number of elements in the vector) : 조회된 값들의 갯수를 출력 / 인스턴스 벡터에서만 사용 가능
- count_values (count number of elements with the same value) : 같은 값을 가지는 요소의 갯수를 출력
- bottomk (smallest k elements by sample value) : 조회된 값들 중에 가장 작은 값들 k 개 출력
- topk (largest k elements by sample value) : 조회된 값들 중에 가장 큰 값들 k 개 출력
- quantile (calculate φ-quantile (0 ≤ φ ≤ 1) over dimensions) : 조회된 값들을 사분위로 나눠서 (0 < $ < 1)로 구성하고, $에 해당 하는 요소들을 출력
#
node_memory_Active_bytes
# 출력 값 중 Top 3
topk(3, node_memory_Active_bytes)
# 출력 값 중 하위 3
bottomk(3, node_memory_Active_bytes)
bottomk(3, node_memory_Active_bytes>0)
# node 그룹별: by
node_cpu_seconds_total
node_cpu_seconds_total{mode="user"}
node_cpu_seconds_total{mode="system"}
avg(node_cpu_seconds_total)
avg(node_cpu_seconds_total) by (instance)
avg(node_cpu_seconds_total{mode="user"}) by (instance)
avg(node_cpu_seconds_total{mode="system"}) by (instance)
#
nginx_http_requests_total
sum(nginx_http_requests_total)
sum(nginx_http_requests_total) by (instance)
# 특정 내용 제외하고 출력 : without
nginx_http_requests_total
sum(nginx_http_requests_total) without (instance)
sum(nginx_http_requests_total) without (instance,container,endpoint,job,namespace)

- Time series selectors : Instant/Range vector selectors, Time Durations, Offset modifier, @ modifier - Link
- 인스턴스 벡터 Instant Vector : 시점에 대한 메트릭 값만을 가지는 데이터 타입
- 레인지 벡터 Range Vector : 시간의 구간을 가지는 데이터 타입
- 시간 단위 : ms, s, m(주로 분 사용), h, d, w, y
# 시점 데이터
node_cpu_seconds_total
# 15초 마다 수집하니 아래는 지난 4회차/8회차의 값 출력
node_cpu_seconds_total[1m]
node_cpu_seconds_total[2m]
- 활용
# 서비스 정보 >> 네임스페이스별 >> cluster_ip 별
kube_service_info
count(kube_service_info)
count(kube_service_info) by (namespace)
count(kube_service_info) by (cluster_ip)
# 컨테이너가 사용 메모리 -> 파드별
container_memory_working_set_bytes
sum(container_memory_working_set_bytes)
sum(container_memory_working_set_bytes) by (pod)
topk(5,sum(container_memory_working_set_bytes) by (pod))
topk(5,sum(container_memory_working_set_bytes) by (pod))/1024/1024
6. 그라파나 Grafana
☞ 소개 및 웹 접속 : TSDB 데이터를 시각화, 다양한 데이터 형식 지원(메트릭, 로그, 트레이스 등) - Docs , Blog , Toturials ,
- Grafana open source software enables you to query, visualize, alert on, and explore your metrics, logs, and traces wherever they are stored.
- Grafana OSS provides you with tools to turn your time-series database (TSDB) data into insightful graphs and visualizations.
- 그라파나는 시각화 솔루션으로 데이터 자체를 저장하지 않음 → 현재 실습 환경에서는 데이터 소스는 프로메테우스를 사용
- 접속 정보 확인 및 로그인 : 기본 계정 - admin / prom-operator
# 그라파나 버전 확인
kubectl exec -it -n monitoring sts/kube-prometheus-stack-grafana -- grafana cli --version
grafana cli version 11.5.1
# ingress 확인
kubectl get ingress -n monitoring kube-prometheus-stack-grafana
kubectl describe ingress -n monitoring kube-prometheus-stack-grafana
# ingress 도메인으로 웹 접속 : 기본 계정 - admin / prom-operator
echo -e "Grafana Web URL = https://grafana.$MyDomain"
- 우측 상단 : admin 사용자의 개인 설정
- 기본 대시보드 확인

1. Search dashboards : 대시보드 검색
2. Starred : 즐겨찾기 대시보드
3. Dashboards : 대시보드 전체 목록 확인
4. Explore : 쿼리 언어 PromQL를 이용해 메트릭 정보를 그래프 형태로 탐색
5. Alerting : 경고, 에러 발생 시 사용자에게 경고를 전달
6. Connections : 설정, 예) 데이터 소스 설정 등
7. Administartor : 사용자, 조직, 플러그인 등 설정
- Connections → Your connections : 스택의 경우 자동으로 프로메테우스를 데이터 소스로 추가해둠 ← 서비스 주소 확인

# 서비스 주소 확인
kubectl get svc,ep -n monitoring kube-prometheus-stack-prometheus
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kube-prometheus-stack-prometheus ClusterIP 10.100.85.54 <none> 9090/TCP,8080/TCP 173m
NAME ENDPOINTS AGE
endpoints/kube-prometheus-stack-prometheus 192.168.3.42:9090,192.168.3.42:8080 173m
- 해당 데이터 소스 접속 확인
# 테스트용 파드 배포
cat <<EOF | kubectl create -f -
apiVersion: v1
kind: Pod
metadata:
name: netshoot-pod
spec:
containers:
- name: netshoot-pod
image: nicolaka/netshoot
command: ["tail"]
args: ["-f", "/dev/null"]
terminationGracePeriodSeconds: 0
EOF
kubectl get pod netshoot-pod
# 접속 확인
kubectl exec -it netshoot-pod -- nslookup kube-prometheus-stack-prometheus.monitoring
kubectl exec -it netshoot-pod -- curl -s kube-prometheus-stack-prometheus.monitoring:9090/graph -v ; echo
# 삭제
kubectl delete pod netshoot-pod
☞ 대시보드 사용 : 기본 대시보드와 공식 대시보드 가져오기
기본 대시보드
- 스택을 통해서 설치된 기본 대시보드 확인 : Dashboards → Browse
- (대략) 분류 : 자원 사용량 - Cluster/POD Resources, 노드 자원 사용량 - Node Exporter, 주요 애플리케이션 - CoreDNS 등
- 확인해보자 - K8S / CR / Cluster, Node Exporter / Use Method / Cluster
- [Kubernetes / Views / Global] Dashboard → New → Import → 15757 력입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭

- [1 Kubernetes All-in-one Cluster Monitoring KR] Dashboard → New → Import → 17900 입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭


아래 값 출력되게 수정해보자!

- 해당 패널에서 Edit → 아래 수정 쿼리 입력 후 Run queries 클릭 → 상단 Save 후 Apply
sum by (node) (irate(node_cpu_seconds_total{mode!~"guest.*|idle|iowait", node="$node"}[5m]))node_cpu_seconds_total
node_cpu_seconds_total{mode!~"guest.*|idle|iowait"}
avg(node_cpu_seconds_total{mode!~"guest.*|idle|iowait"}) by (node)
avg(node_cpu_seconds_total{mode!~"guest.*|idle|iowait"}) by (instance)
# 수정
sum by (instance) (irate(node_cpu_seconds_total{mode!~"guest.*|idle|iowait", instance="$instance"}[5m]))
# 수정 : 메모리 점유율
(node_memory_MemTotal_bytes{instance="$instance"}-node_memory_MemAvailable_bytes{instance="$instance"})/node_memory_MemTotal_bytes{instance="$instance"}
# 수정 : 디스크 사용률
sum(node_filesystem_size_bytes{instance="$instance"} - node_filesystem_avail_bytes{instance="$instance"}) by (instance) / sum(node_filesystem_size_bytes{instance="$instance"}) by (instance)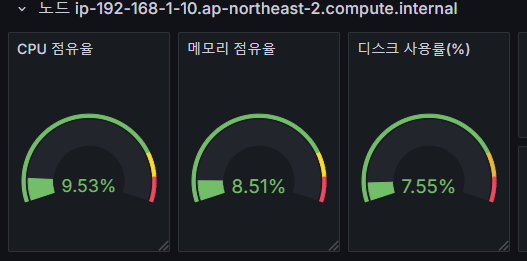
상단 네임스페이스와 파드 정보 필터링 출력되게 수정해보자!
- 오른쪽 상단 Edit → Settings → Variables 아래 namesapce, pod 값 수정 ⇒ 수정 후 Save dashboard 클릭

- namespace 경우 : kube_pod_info 로 수정

- namespace 오른쪽 Showing usages for 클릭 시 → 맨 하단에 pod variable 가 namespace 를 하위에 종속? 관계 확인


파드의 리소스 할당 제한 제대로 표시 해보자!
- 리소스 할당 제한 패널 edit → Save dashboard
- CPU
# 기존
sum(kube_pod_container_resource_limits_cpu_cores{pod="$pod"})
# 변경 전 쿼리 시도
kube_pod_container_resource_limits_cpu_cores
kube_pod_container_resource_limits
kube_pod_container_resource_limits{resource="cpu"}
# 변경
sum(kube_pod_container_resource_limits{resource="cpu", pod="$pod"})- Memory
# 기존
sum(kube_pod_container_resource_limits_memory_bytes{pod="$pod"})
# 변경
sum(kube_pod_container_resource_limits{resource="memory", pod="$pod"})

- default 네임스페이스에 nginx 파드 정보 확인 : 쿼리 수정 후 바로 적용 안되니, 파드를 선택 후 재선택 하자..
- [Node Exporter Full] Dashboard → New → Import → 1860 입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭

- [Node Exporter for Prometheus Dashboard based on 11074] 15172

- kube-state-metrics-v2 가져와보자 : Dashboard ID copied! (13332) 클릭 - 링크
- [kube-state-metrics-v2] Dashboard → New → Import → 13332 입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭
- [Amazon EKS] AWS CNI Metrics 16032 - 링크
# PodMonitor 배포
cat <<EOF | kubectl create -f -
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
name: aws-cni-metrics
namespace: kube-system
spec:
jobLabel: k8s-app
namespaceSelector:
matchNames:
- kube-system
podMetricsEndpoints:
- interval: 30s
path: /metrics
port: metrics
selector:
matchLabels:
k8s-app: aws-node
EOF
# PodMonitor 확인
kubectl get podmonitor -n kube-system
☞ NGINX 애플리케이션 모니터링 대시보드 추가
- 그라파나에 12708 대시보드 추가 - Link
# scale out
kubectl scale deployment nginx --replicas 9
☞ [중급] Panel 패널 - Link
https://grafana.com/docs/grafana/latest/panels-visualizations/visualizations/
- Graphs & charts
- Time series is the default and main Graph visualization.
- State timeline for state changes over time.
- Status history for periodic state over time.
- Bar chart shows any categorical data.
- Histogram calculates and shows value distribution in a bar chart.
- Heatmap visualizes data in two dimensions, used typically for the magnitude of a phenomenon.
- Pie chart is typically used where proportionality is important.
- Candlestick is typically for financial data where the focus is price/data movement.
- Gauge is the traditional rounded visual showing how far a single metric is from a threshold.
- Stats & numbers
- Misc
- Table is the main and only table visualization.
- Logs is the main visualization for logs.
- Node graph for directed graphs or networks.
- Traces is the main visualization for traces.
- Flame graph is the main visualization for profiling.
- Canvas allows you to explicitly place elements within static and dynamic layouts.
- Geomap helps you visualize geospatial data.
- Widgets
- Dashboard list can list dashboards.
- Alert list can list alerts.
- Text can show markdown and html.
- News can show RSS feeds.
- 실습 준비 : 신규 대시보스 생성 → 패널 생성(Code 로 변경) → 쿼리 입력 후 Run queries 클릭 후 오른쪽 상단 Apply 클릭 → 대시보드 상단 저장
1. Time series : 아래 쿼리 입력 후 오른쪽 입력 → Title(노드별 5분간 CPU 사용 변화율)
node_cpu_seconds_total
rate(node_cpu_seconds_total[5m])
sum(rate(node_cpu_seconds_total[5m]))
sum(rate(node_cpu_seconds_total[5m])) by (instance)- 상단 : 최근 30분, 5초 간격 Auto 쿼리
2. Bar chart : Add → Visualization 오른쪽(Bar chart) ⇒ 쿼리 Options : Legend(Auto), Format(Table), Type(Instance) → Title(네임스페이스 별 디플로이먼트 갯수)
kube_deployment_status_replicas_available
count(kube_deployment_status_replicas_available) by (namespace)
3. Stat : Add → Visualization 오른쪽(Stat) → Title(nginx 파드 수)
kube_deployment_spec_replicas
kube_deployment_spec_replicas{deployment="nginx"}
# scale out
kubectl scale deployment nginx --replicas 6
4. Gauge : Add → Visualization 오른쪽(Gauge) → Title(노드 별 1분간 CPU 사용률)
node_cpu_seconds_total
node_cpu_seconds_total{mode="idle"}
node_cpu_seconds_total{mode="idle"}[1m]
rate(node_cpu_seconds_total{mode="idle"}[1m])
avg(rate(node_cpu_seconds_total{mode="idle"}[1m])) by (instance)
1 - (avg(rate(node_cpu_seconds_total{mode="idle"}[1m])) by (instance))
5. Table : Add → Visualization 오른쪽(Table) ⇒ 쿼리 Options : Format(Table), Type(Instance) → Title(노드 OS 정보)
node_os_info- Transform data → Organize fields by name : id_like, instance, name, pretty_name
6. 원하는 위치로 배치


7. 그라파나 얼럿 Alert
그라파나 9.4 버전이 2월 28일 출시 - 링크 ⇒ Alerting 기능이 강화되었고, 이미지 알람 기능도 제공 - 링크
그라파나 9.5 버전이 Alerting 기능 업데이트 - 링크
☞ 그라파나 얼럿 Docs - 링크 Workshop Blog1 Blog2

1. Contact points → Add contact point 클릭
- Integration : 슬랙
- Webhook URL : 아래 주소 입력
https://hooks.slack.com/services/T03G23CRBNZ/B08DV377X3N/w7vfr0Ghxxxxxxxxxxxxxxxxxxxxxxx- Optional Slack settings → Username : 메시지 구분을 위해서 각자 자신의 닉네임 입력

- 오른쪽 상단 : Test 해보고 저장

2. Notification policies : 기본 정책 수정 Edit - Default contact point(slack)
3. 그라파나 → Alerting → Alert ruels → Create alert rule : Name(nginx alert) - nginx 웹 요청 1분 동안 누적 60 이상 시 Alert 설정
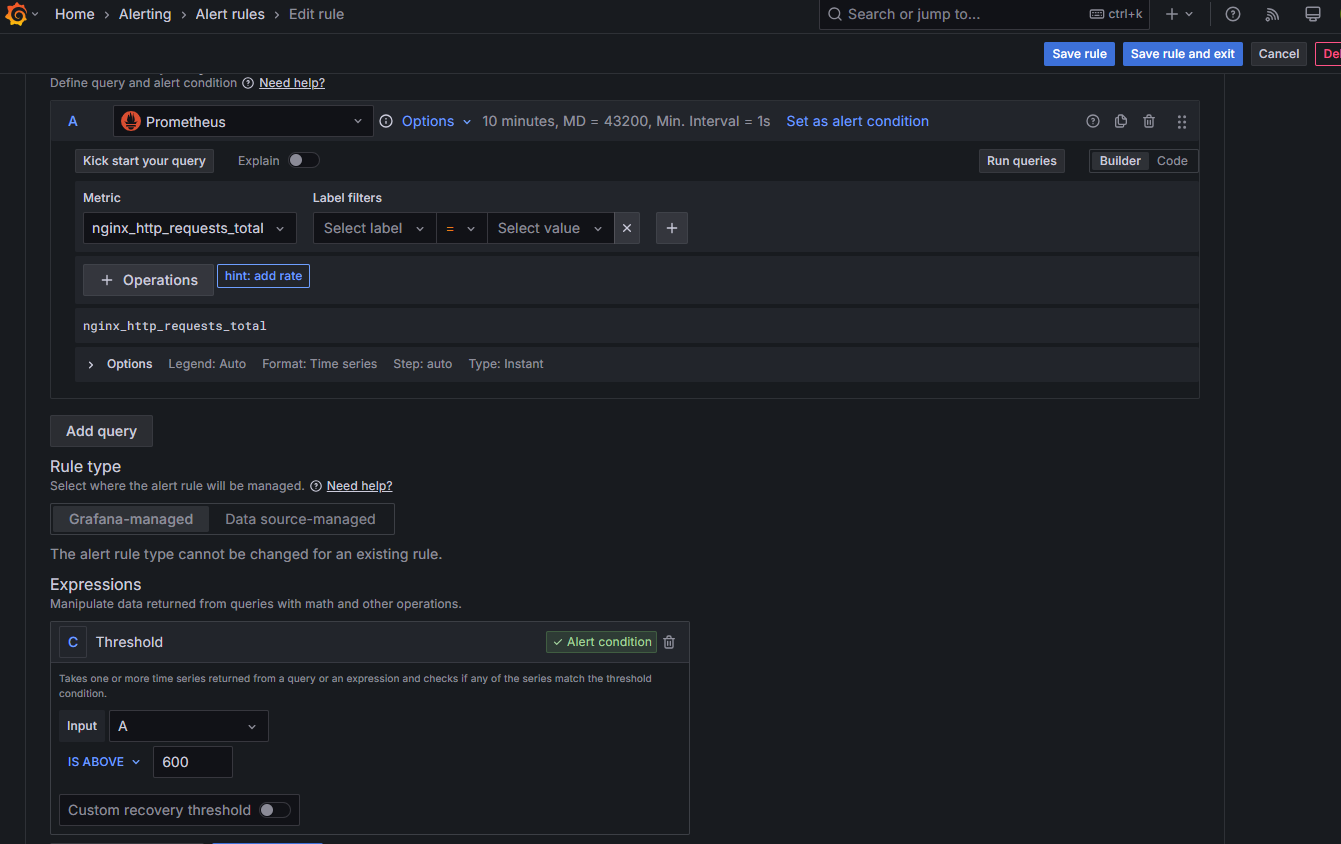
- 아래 Folder 과 Evaluation group(1m), Pending period(1m) 은 +Add new 클릭 후 신규로 만들어 주자
Configure notifications : Contack point(slack) ⇒ 오른쪽 상단 Save and exit 클릭

4.nginx 반복 접속 실행 후 슬랙 채널 알람 확인
while true; do curl -s https://nginx.$MyDomain -I | head -n 1; date; done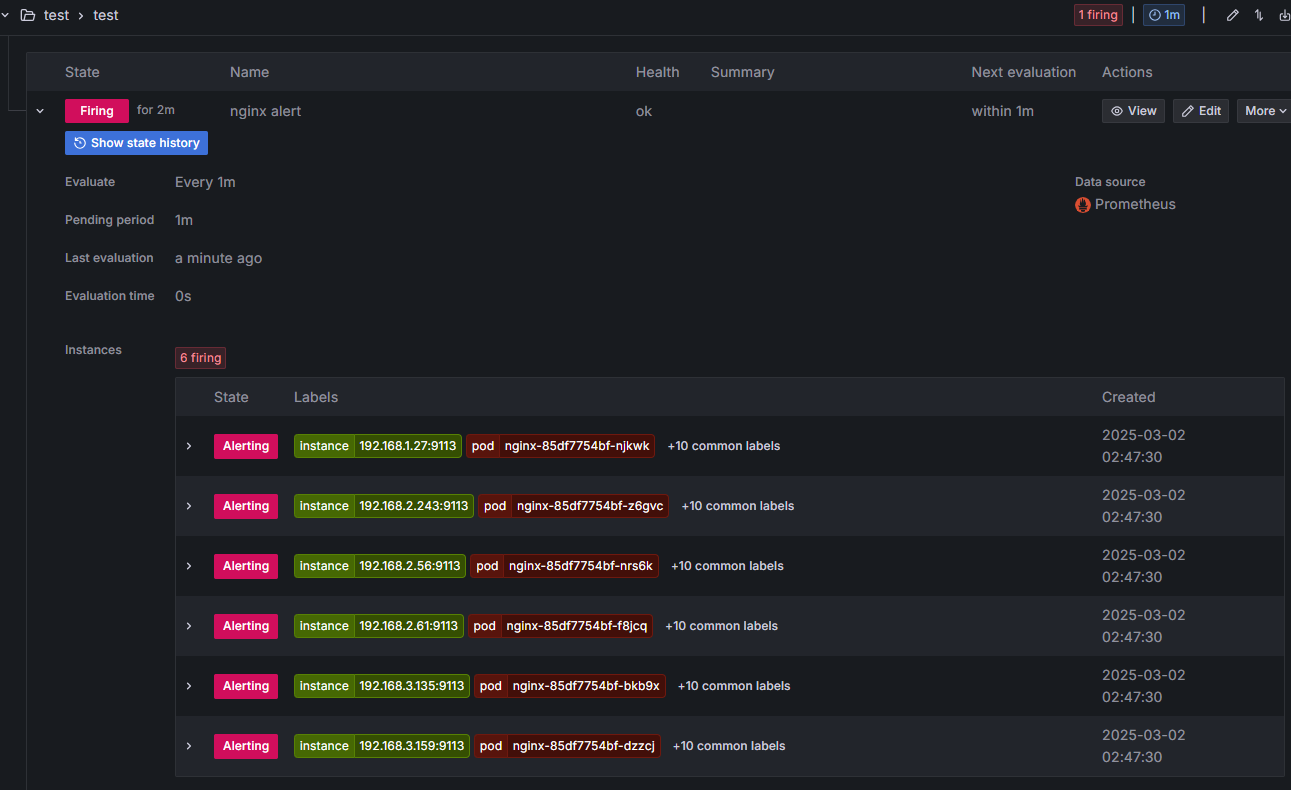

(실습 완료 후) 자원 삭제
삭제 : [운영서버 EC2]에서 원클릭 삭제 진행
# eksctl delete cluster --name $CLUSTER_NAME && aws cloudformation delete-stack --stack-name $CLUSTER_NAME
nohup sh -c "eksctl delete cluster --name $CLUSTER_NAME && aws cloudformation delete-stack --stack-name $CLUSTER_NAME" > /root/delete.log 2>&1 &
# (옵션) 삭제 과정 확인
tail -f delete.logAWS EC2 → 볼륨 : 남아 있는 볼륨(프로메테우스, 그라파나용 PVC/PV로 생성된) 삭제하자!
(옵션) 로깅 삭제 : 위에서 삭제 안 했을 경우 삭제
# EKS Control Plane 로깅(CloudWatch Logs) 비활성화
eksctl utils update-cluster-logging --cluster $CLUSTER_NAME --region $AWS_DEFAULT_REGION --disable-types all --approve
# 로그 그룹 삭제 : 컨트롤 플레인
aws logs delete-log-group --log-group-name /aws/eks/$CLUSTER_NAME/cluster
---
# 로그 그룹 삭제 : 데이터 플레인
aws logs delete-log-group --log-group-name /aws/containerinsights/$CLUSTER_NAME/application
aws logs delete-log-group --log-group-name /aws/containerinsights/$CLUSTER_NAME/dataplane
aws logs delete-log-group --log-group-name /aws/containerinsights/$CLUSTER_NAME/host
aws logs delete-log-group --log-group-name /aws/containerinsights/$CLUSTER_NAME/performance'AEWS study' 카테고리의 다른 글
| 5주차 - EKS Autoscaling - #2 (0) | 2025.03.08 |
|---|---|
| 5주차 - EKS Autoscaling - #1 (0) | 2025.03.07 |
| 4주차 - EKS Observability - #1 (0) | 2025.02.28 |
| 3주차 - EKS Storage, Managed Node Groups - #2 (0) | 2025.02.22 |
| 3주차 - EKS Storage, Managed Node Groups - #1 (0) | 2025.02.22 |